










What Is White Box Testing? 5 Popular White Box Testing Techniques

 (31 votes, average: 4.74 out of 5)
(31 votes, average: 4.74 out of 5)According to HackerRank’s 2019 DeveloperSkills Report, 60% of the survey participants say that the most common production bugs are deploying untested or broken code
Before making their market debut, code-based products — apps, games, operating systems, a piece of hardware equipment with code, etc. — must undergo software testing to identify and fix bugs. White box testing, the process of identifying vulnerabilities, can be done by testing the functionality based on requirements or by inspecting the quality attributes of the designed product. This is a key component of the software development lifecycle (SDLC).
White box testing techniques involve inspecting the binaries and code for vulnerabilities or anomalies. The tester assesses not just how the application reacts to various inputs but determines why an application behaves a certain way. White box testing is also known by other names like structural testing, code-based testing, open box testing, and glass box testing. These are terms that indicate how this testing method analyzes a product’s internal workings and overall structure.
What Is White Box Testing?
You can carry out software testing for each module of code (unit testing) and for multiple modules (integration testing) before testing the overall system. There are three primary approaches that testers use to test a product:
- Black box testing,
- White box testing, and
- Grey box testing.
In black box testing, testers don’t have access to assess the application’s code or structural components. They find bugs solely based on the application’s behavior when tested against various parameters. With white box testing, the evaluator needs to be well versed in the coding language used. The process is a lot more transparent because the tester can observe and assess:
- How the input flows through the code,
- The logical paths followed,
- The purpose of conditional statements,
- Poorly structured coding functionalities.
Grey box testing uses a mix of both black box and white box testing techniques. It operates on partial knowledge of the internal workings of an application.
How White Box Testing Works
White box testing involves executing a series of predefined inputs and observing the results. If the outputs show any abnormalities, then the bugs are reported. Test cases are designed and run, and the process is repeated until all major bugs are eliminated. The tester must also have an in-depth knowledge of secure coding practices to dispose of any insecure statements where an attacker can inject code or manipulate the application to extract further information.
Consider the following pseudocode and example test cases that you can execute:
example func(int a, int b)
{
if (a>b)
Print ("The first value you entered is higher!");
else if (a<b)
Print ("The second value you entered is higher!");
else if (a=b)
Print ("The values entered are equal!);
}The test cases for the above could include values such as:
- a=56, b= 31
- a=5, b=51
- a=-2, b=5
- a=7, b=7
How White Box Testing and Secure Code Review Differ
Although secure code review and white box testing both share comparable goals and the testing methods involve finding bugs in the source code, they are two distinct methodologies.
- Secure code review focuses primarily on auditing the source code to find security vulnerabilities and to ensure that proper security controls have been used in the right places.
- White box testing includes a wider scope that may include strengthening security in addition to testing other aspects such as performance, code design, usability, and so on.
Additionally, secure code review, at its core, doesn’t involve physically testing the product. It involves reading the code and analyzing it to identify security weaknesses. In white box testing, on the other hand, the code is physically tested against the defined test suites. So, to summarize, white box testing involves using the product code to test it, whereas secure code review only involves reading the code to evaluate it for vulnerabilities.
Breaking Down the 5 White Box Testing Techniques
There are several white box testing techniques with varying coverage criteria, and different resources categorize the techniques differently in terms of the number of criteria. For the purpose of this article, we’ll identify the techniques by the following five criteria:
- Statement coverage
- Branch coverage
- Condition coverage
- Path testing
- Data flow testing
The subsequent sections will concentrate on gaining an overview of how these techniques work before moving on to some tools that you can use to perform white box testing.
1. Statement Coverage
A statement is a line of code or an instruction. The ratio of the number of executed statements to the total number of statements is what determines the coverage. The higher the ratio, the better the statement coverage. Ideally, every line of code should execute at least once — and making sure that happens is the overall objective of this particular testing process.
Let’s go back to the example pseudocode we covered earlier for a moment. If we run the first test case (a=56, b=31), what is the statement coverage?
1. example func(int a, int b) {
2. if (a>b)
3. Print ("The first value you entered is higher!");
4. else if (a<b)
5. Print ("The second value you entered is higher!");
6. else if (a=b)
7. Print ("The values entered are equal!);}Three out of seven statements execute in the above test case. Hence, in this example, the coverage is around 42.85%. However, the minimum acceptable coverage goal is typically around 70-80% in most projects. If the coverage falls short, write new test cases and re-test the code.
2. Branch Coverage
Branch coverage is the ratio of the number of executed branches to the total number of branches in the program. Branches refer to the choices arising out of a decision statement (a conditional loop, an if-else clause, etc.). It also covers unconditional branches — and, in an ideal scenario, the objective is that every branch should execute at least once to give 100% coverage.
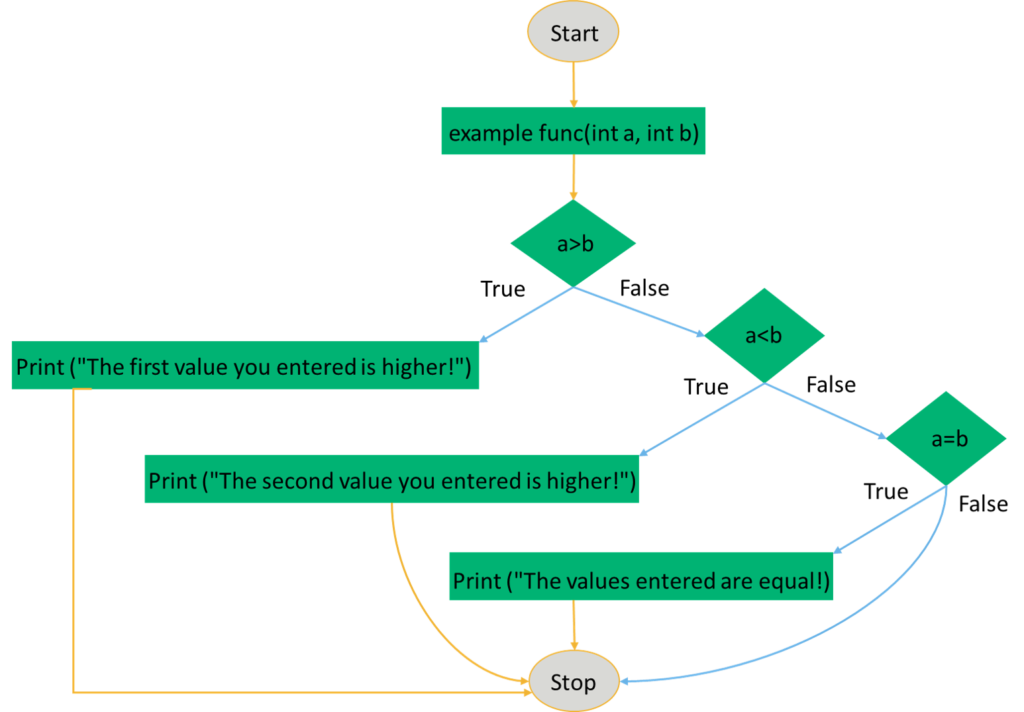
Let’s visualize the example pseudocode with the help of a flowchart:
In the illustration above, there’s a total of six branches (highlighted in blue). If you consider the first test case (a-56, b=31), only the true branch of the first condition is executed. The branch coverage is 16.67%. Once you consider the second test case (a=5, b=51), then you cover three out of six branches. This means that branch coverage is at 50%.
3. Condition Coverage
In a programming language, conditional constructs execute statements based on whether a Boolean expression evaluates to true or false. With condition coverage, also known as predicate coverage, you want all of the conditions (each component of the Boolean expressions) in the program to evaluate as both true and false at least once. Condition coverage computes as the ratio of the number of conditions that are both true and false to the total number of conditions.
Consider the following code:
void example (float x, float y)
{
if ((x==0) || y>0)
y=y/x; // statement executed if condition is true
else
// statement executed if the above expression is false
}In this example, at least one test case where the expression (including the individual sub-expressions) evaluates to true and false (so that the else condition executes) should be considered. Note that if the condition x=0 evaluates to true, then the next statement will result in a division by zero error. It’s essential to determine all possibilities of outcomes to rule out any anomalies.
4. Path Testing
A path is the route from the starting node to the terminal node of a control flow graph. There can be several paths and multiple terminal nodes. In the presence of loops, if you’re trying to cover all possible paths, the number of paths can get extremely large.
In path testing, all linearly independent paths should be executed by the test suite for the tests to achieve path coverage. To determine the number of linearly independent paths of a program, you can use McCabe’s cyclomatic metric. This software quality metric provides a quantitative measure of testing difficulty and reliability, and the higher the resulting number, the more challenging and complex the code.
Consider the code snippet below and the ensuing control flow graph (CFG):
1. while (a>b){
2. a=a-1;
3. b=b+a;}
4. c=a+b;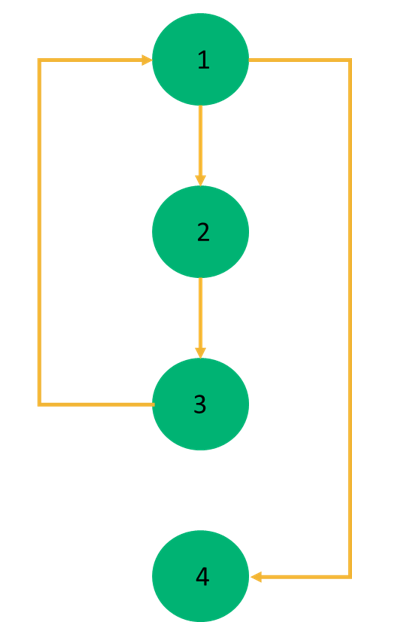
For a control flow graph G, the cyclomatic complexity V(G) is calculated as V(G)=E-N+2, where N is the number of nodes in G, and E is the number of edges. In this example, there are four edges and four nodes, so the cyclomatic complexity value is 2. This indicates that there are two linearly independent paths, so you’ll need at least two test cases.
However, if for any CFG, the McCabe metric is a higher value like 12, it implies that a minimum of 12 test cases will be required, increasing not only the level of difficulty but also the likelihood of overlooking potential bugs. Moreover, you can only compute the least number of test cases required, but that doesn’t tell us how to derive those test cases. It is, therefore, not a practical approach for larger programs.
5. Data Flow Testing
Data flow testing focuses on where variables are defined and used within the program. It analyzes how the data flows through these variables and can spot anomalies in logical constructs within the program. For instance, it can help you detect attempts to use a variable without first initializing it or not using an initialized variable throughout the program.
Let’s consider the following example pseudocode:
1. read (a, b)
2. if(a>=b)
3. x = a+1
4. else x = b-1
5. print x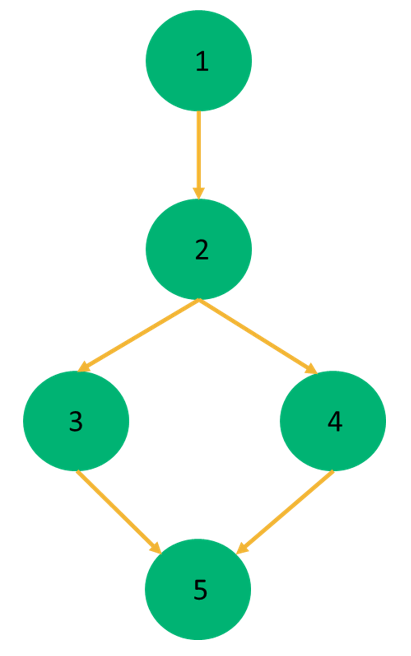
Now, let’s consider the CFG for the above example:
If the value of a variable decides an execution path (for example, in a while loop), then it’s considered to be a predicate use (p-use). If the value of a variable calculates an output, or for defining another variable, it’s considered as computation use (c-use).
Here, the variables a and b are defined on node 1 and used on nodes 2,3 and 2,4 respectively. The variable x is defined on nodes 3, 4, and used on node 5.
The Advantages and Disadvantages of White Box Testing
White box testing is typically useful for mission-critical applications and systems due to its resource-intensive and rigorous nature. While it gives us more visibility into the internal workings of an application, there are some overheads to consider as well. Let’s dive into the benefits and drawbacks of using this testing methodology.
Advantages of White Box Testing Technique
Some of the advantages of using white box testing are:
- Efficient Code Optimization: You can optimize the resultant code to remove bugs and based upon requirements.
- Easy Automation: White box testing automates easily and integrates with the SDLC process to detect anomalies early on in the process.
- Comprehensive Testing: White box testing, based upon the specified minimum acceptable coverage requirement, is a highly thorough process that ensures the assessment of all structural elements and code.
Disadvantages of White Box Testing Techniques
As with virtually everything in life, white box testing isn’t perfect and has limitations. Some of the shortcomings include:
- Complexity: White box testing can be a complex and expensive process depending on the size of application and the scope of testing.
- Cost and Effort Intensive: It may get challenging to find the right resources with the appropriate skill set and willingness to conduct exhaustive testing.
- Time Consuming: White box testing is a time-consuming process, especially for larger applications with higher code coverage criteria. This type of testing can introduce unexpected delays, especially if any severe bugs are discovered during the later stages of the software development lifecycle.
- Susceptible to Human-Errors: There is always the possibility of human-based error, particularly when conducting manual tests.
White Box Testing Tools
As with testing techniques, there are numerous tools that can be deployed for white box testing. Some of the more common ones include:
- Veracode — Veracode offers a scalable, automated testing solution that integrates with the development process to minimize the cost of fixing bugs.
- RCUNIT — RCUNIT is a framework for testing programs written in C. It’s free and can be used in accordance with the terms of the MIT License.
- NUnit — NUnit is an open-source unit testing framework for applications written using the .Net language.
- JUnit — Junit is a testing framework for Java applications.
- PyUnit — PyUnit, a Python language version of Junit, is a Python unit testing framework.
Depending on the programming language, other tools like JsUnit, CppUnit, EMMA, Googletest, cfix, may also be useful.
Wrapping Up
Hopefully, by now, you have a fair understanding of what white box testing is, how some of the white box testing techniques work, and what tools are available in the market to use. We’ve also discussed what white box testing is not, how it’s different from other testing techniques such as black box, grey box, and how the process differs from secure code review.
When deliberating which technique is best for testing your application, consider each method’s pros and cons and make a choice based upon your individual requirements and resource availability. After testing the code, most organizations and developers sign their code using a code signing certificate before shipping the product. This is done to assert their identity, to assure users that the code is unaltered, and to avoid the Windows SmartScreen “Unknown Publisher” warning.






2018 Top 100 Ecommerce Retailers Benchmark Study
in Web Security5 Ridiculous (But Real) Reasons IoT Security is Critical
in IoTComodo CA is now Sectigo: FAQs
in SectigoStore8 Crucial Tips To Secure Your WordPress Website
in WordPress SecurityWhat is Always on SSL (AOSSL) and Why Do All Websites Need It?
in Encryption Web SecurityHow to Install SSL Certificates on WordPress: The Ultimate Migration Guide
in Encryption Web Security WordPress SecurityThe 7 Biggest Data Breaches of All Time
in Web SecurityHashing vs Encryption — The Big Players of the Cyber Security World
in EncryptionHow to Tell If a Website is Legit in 10 Easy Steps
in Web SecurityWhat Is OWASP? What Are the OWASP Top 10 Vulnerabilities?
in Web Security